모두가 GPU를 탓했다. 추론 지연? VRAM 부족? 배치 스케줄링 문제? 진짜 병목은 정규식이었다.
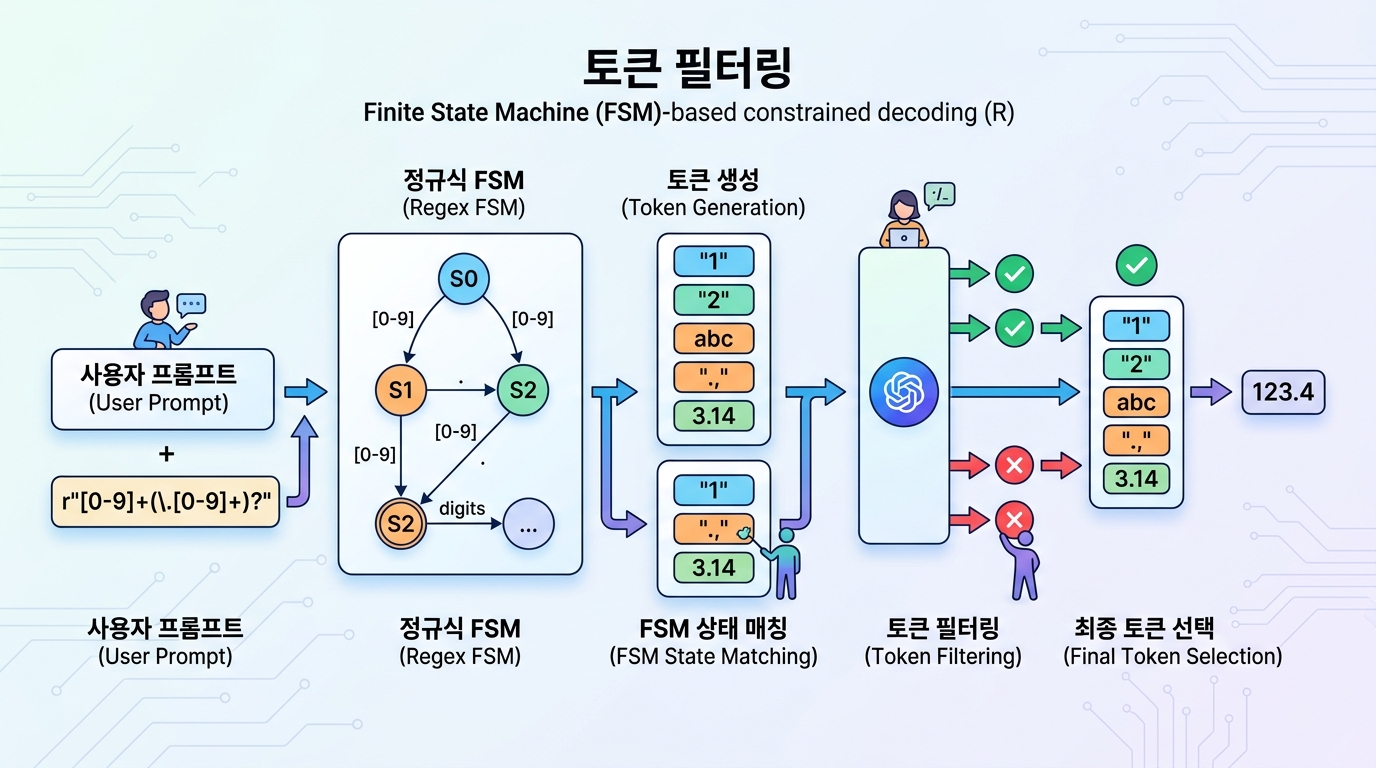
Hacker News에 올라온 'Finding all regex matches has always been O(n²)'라는 글이 AI 엔지니어링 커뮤니티를 뒤흔들고 있다. 정규식(Regular Expression) 매칭의 시간 복잡도가 본질적으로 O(n²)라는 사실 자체는 컴퓨터 과학 교과서에 실린 오래된 이야기다. 그런데 이 낡은 정리가 지금 다시 소환된 데는 이유가 있다. LLM의 구조화 출력, JSON Mode와 Function Calling, 을 가능하게 하는 핵심 엔진이 바로 정규식 기반 유한 상태 머신(FSM)이기 때문이다.
정규식 FSM, 구조화 출력의 숨은 심장
OpenAI의 JSON Mode, Anthropic의 Tool Use, 오픈소스 진영의 Outlines와 vLLM. 이들이 LLM 출력을 깔끔한 JSON이나 함수 호출 형식으로 뽑아내는 원리는 생각보다 단순하다. 모델이 토큰을 생성할 때마다 정규식 기반 FSM이 "이 토큰 다음에 올 수 있는 토큰"을 걸러낸다. Constrained Decoding이라 불리는 이 기법이 AI 에이전트 파이프라인의 안정성을 떠받치는 핵심 레이어다.
문제는 이 FSM의 연료인 정규식 매칭이 O(n²)라는 데 있다. 단일 매치를 찾는 건 O(n)으로 끝난다. 하지만 문자열 안에서 가능한 모든 매치를 탐색해야 할 때, 시작 위치마다 매칭을 반복해야 하므로 복잡도가 O(n²)로 뛴다. 토큰 수백 개짜리 짧은 응답에서는 차이를 느끼기 어렵다. 그러나 AI 에이전트가 수천 토큰 규모의 복잡한 JSON 스키마를 생성하거나, 중첩된 Function Calling 체인을 소화해야 할 때는 상황이 완전히 달라진다.
A100 여덟 장이 노는 동안, CPU 싱글 코어가 끙끙댔다
Hacker News 댓글에서 한 vLLM 기여자가 털어놓았다. "A100 여덟 장을 풀로 돌리는 동안 정규식 엔진이 싱글 코어에서 끙끙대고 있었다는 걸, 프로파일링하고 나서야 알았다." 구조화 출력의 정규식 처리는 대부분 CPU에서 동기적으로 실행된다. GPU 활용률 그래프만 들여다보는 엔지니어들이 이 병목을 놓칠 수밖에 없는 구조다.
Outlines 프로젝트의 GitHub 이슈 트래커에서도 관련 논의가 뜨겁다. 복잡한 JSON Schema를 정규식으로 변환할 때 FSM 상태 수가 폭발적으로 불어나는 현상이 반복 보고되고 있다. 스키마에 oneOf, anyOf 같은 유니온 타입이 끼어들면 정규식 패턴 자체가 기하급수적으로 복잡해지고, 매칭 비용도 함께 치솟는다.
에이전트 멀티스텝 시대, O(n²)가 직렬로 쌓인다
이 문제가 학술적 호기심에 머물지 않는 건 AI 에이전트 파이프라인의 구조 때문이다. 요즘 프로덕션 AI 시스템은 한 번의 LLM 호출로 끝나지 않는다. 에이전트가 도구를 호출하고, 결과를 파싱하고, 다시 다음 함수를 호출하는 멀티스텝 파이프라인이 표준이 됐다. 각 단계마다 구조화 출력이 필요하고, 매 단계마다 정규식 FSM이 작동한다. O(n²)가 직렬로 곱해지는 셈이다.
판교의 한 AI 스타트업 CTO는 이렇게 말했다. "Function Calling 체인이 5단계를 넘어가면 체감 지연이 갑자기 튄다. 모델 추론 시간은 일정한데 전체 파이프라인 레이턴시가 비선형으로 증가하길래, 원인을 추적하다 정규식 매칭 쪽을 의심하게 됐다."
PEG 파서, FSM 캐싱, 모델 내재화, 세 갈래 해법
커뮤니티에서 거론되는 접근법은 크게 세 가지다. 첫째, 정규식 대신 PEG(Parsing Expression Grammar)나 CFG(Context-Free Grammar) 기반 파서로 전환하는 방법. Microsoft의 Guidance 라이브러리가 이 방향을 실험 중이다. 둘째, 정규식 FSM을 사전 컴파일하고 캐싱해 반복 비용을 줄이는 최적화. Outlines 팀이 최근 릴리즈에서 이 전략을 부분 적용했다. 셋째, 구조화 출력 자체를 모델 레벨에서 학습시켜 디코딩 타임 제약을 아예 없애는 방향. OpenAI가 GPT-4o의 Structured Outputs에서 시도하고 있는 접근이다.
어떤 방식이 표준으로 자리 잡을지는 아직 모른다. 분명한 건 하나다. AI 추론 인프라의 성능 병목이 GPU 메모리나 모델 크기 같은 "화려한" 지표 뒤에만 숨어 있지 않다는 것. 수십 년 된 컴퓨터 과학의 기초가 가장 첨단의 AI 파이프라인에서 발목을 다시 잡고 있다. 정규식 한 줄의 복잡도가 에이전트 시스템 전체의 응답 속도를 좌우하는 시대, 인프라 엔지니어라면 알고리즘 교과서를 다시 펼쳐야 할 이유가 생겼다.