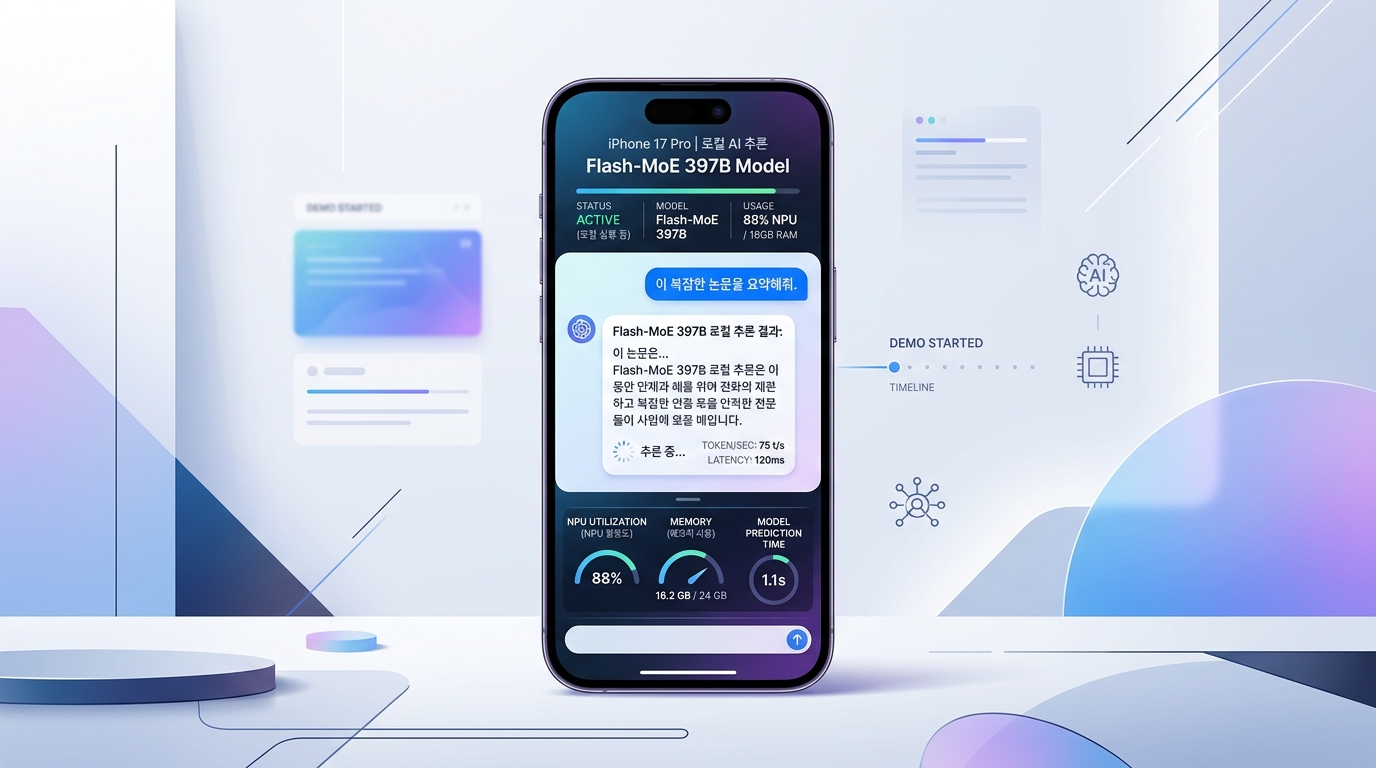
스마트폰 한 대로 4000억 개 파라미터를 돌린다. 허풍이 아니다.
지난주 Hacker News를 뒤흔든 시연 영상 하나가 업계의 통념을 정면으로 깨뜨렸다. iPhone 17 Pro에서 397B 파라미터 규모의 Flash-MoE 모델이 로컬 추론을 수행하는 장면이었다. 클라우드 호출 없이, Wi-Fi조차 끊은 채로. 영상 속 응답 속도는 실시간과 거리가 있었지만, 핵심은 거기에 없다. "수천만 원짜리 GPU 클러스터 없이는 불가능하다"는 전제 자체가 무너졌다는 사실, 그것이 본질이다.
이 시연이 왜 중요한가. 클라우드 없는 초거대 모델 시대가 정말 열리는 건가. 온디바이스 AI 반도체와 모델 경량화를 각각 연구해 온 두 전문가에게 물었다.
"MoE가 판을 바꾼다, 단 조건부로"
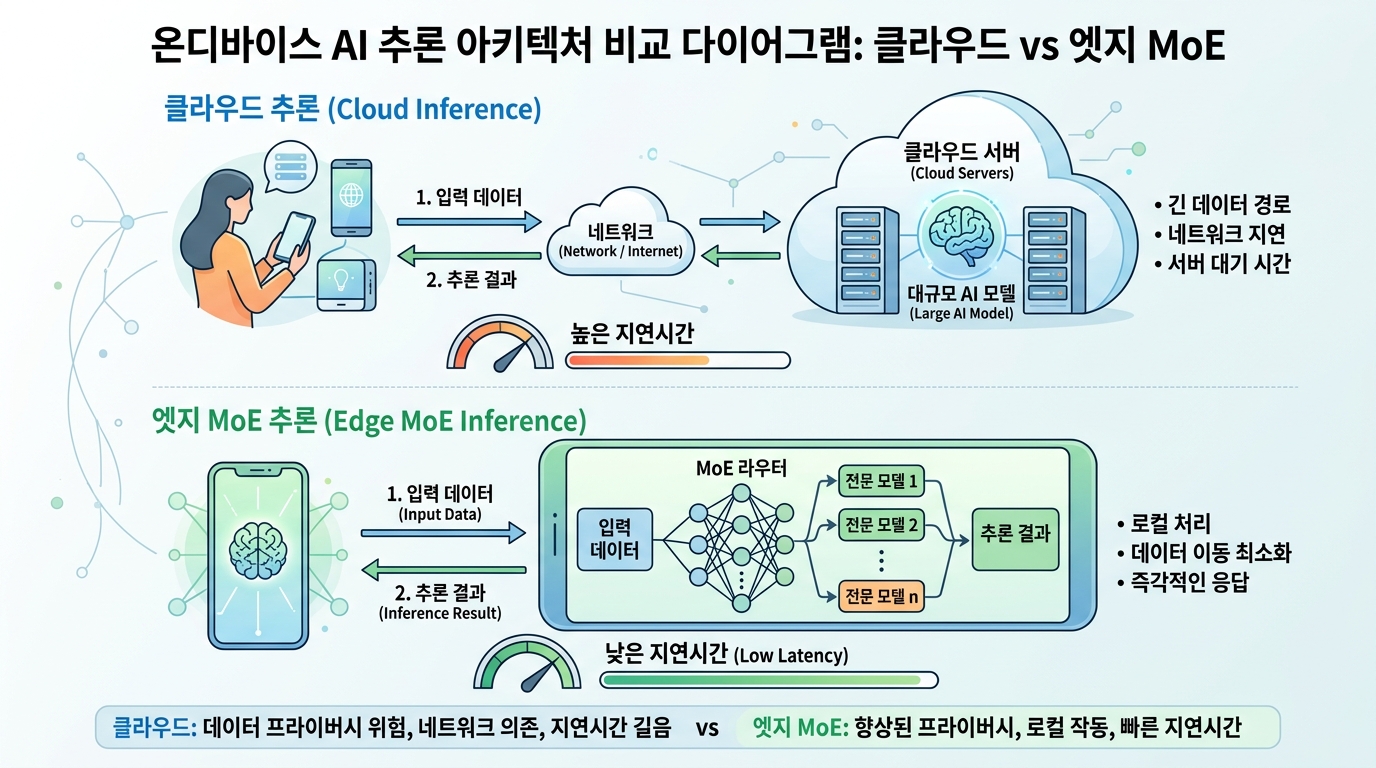
Flash-MoE의 핵심을 이해하려면 Mixture-of-Experts(MoE) 아키텍처를 먼저 짚어야 한다. 전체 파라미터가 397B이라 해도, 한 번의 추론에 활성화되는 건 그 일부에 불과하다. 나머지는 플래시 메모리 속에 잠들어 있다.
모델 경량화 스타트업 A사의 CTO는 이렇게 설명했다.
"397B이라는 숫자에 놀랄 필요가 없습니다. 실제 연산에 참여하는 전문가(expert) 수는 제한적이고, 핵심은 필요한 전문가만 플래시 스토리지에서 얼마나 빠르게 불러오느냐입니다. iPhone 17 Pro의 NVMe급 내부 저장장치 속도가 이걸 가능하게 만든 거죠."
그렇다면 품질은 어떤가. 같은 파라미터 수의 Dense 모델과 동일한 성능을 기대할 수 있느냐는 질문에 그는 솔직했다.
"MoE 모델은 라우팅 설계에 따라 성능 편차가 큽니다. 특정 도메인에서는 Dense 모델을 능가하기도 하지만, 범용 벤치마크에서 동급이라고 단정짓긴 어렵습니다. 다만 방향 자체는 맞습니다. 2년 전만 해도 7B 모델을 폰에서 돌리는 것조차 실험 수준이었으니까요."
클라우드 AI 수익 모델에 균열이 생기나
온디바이스에서 초거대 모델이 돌아간다면, 매월 수십 달러를 내고 클라우드 API를 호출할 이유는 줄어든다. 그러나 이 시나리오를 두고 국내 AI 인프라 투자 심사역 B씨의 시각은 한층 냉정했다.
"투자자 입장에서 이 시연을 보고 곧바로 '클라우드 AI는 끝났다'고 판단하는 건 성급합니다. 현재 엔터프라이즈 AI 워크로드의 90% 이상은 수백 건의 요청을 동시에 처리하는 서빙 환경에서 돌아갑니다. 스마트폰 한 대가 한 명의 사용자를 위해 느린 속도로 추론하는 것과는 차원이 다른 문제예요."
다만 그가 진짜 주목하는 건 비용 구조의 이동이다.
"흥미로운 건, 엣지 추론이 실용화되면 클라우드 업체들의 수익 모델이 '연산 판매'에서 '모델 라이선스'나 '파인튜닝 서비스'로 옮겨갈 수밖에 없다는 점입니다. OpenAI가 이미 디바이스 파트너십을 강화하는 이유도 여기에 있다고 봅니다."
한국 NPU 팹리스, 기회의 창이 열리는가
앞서 엔비디아의 추론 전용 칩 확대를 다룬 적이 있다. 그때 한국 NPU 스타트업들의 틈새가 좁아질 수 있다는 우려가 컸는데, 이번 시연은 정반대 방향의 가능성을 열어준다. 스마트폰, IoT, 자동차 등 엣지 디바이스에 탑재될 추론 전용 칩 수요가 폭증할 수 있기 때문이다.
A사 CTO의 말을 다시 빌린다.
"애플이 자체 뉴럴엔진으로 이걸 해냈다는 건, 다른 안드로이드 OEM들도 비슷한 수준의 NPU를 요구하게 된다는 뜻입니다. 퀄컴, 미디어텍만으로 수요를 감당할 수 있을까요? 한국 팹리스 업체들에게 기회의 창이 열리는 시점일 수 있습니다."
시연에서 상용화까지, 넘어야 할 세 가지 벽
장밋빛 전망만 나열할 수는 없다. 시연과 상용화 사이에는 언제나 간극이 있다.
첫째, 발열과 배터리. 397B 모델 추론 한 세션에 배터리가 얼마나 소모되는지는 아직 공개되지 않았다. 둘째, 메모리 대역폭 병목. 플래시 스토리지에서 전문가를 로딩하는 과정의 지연은 사용자 경험을 직접 좌우한다. 셋째, 보안. 모델 가중치 전체가 디바이스에 저장된다면, 모델 탈취 리스크도 함께 커진다.
B씨는 바로 이 지점을 꼬집었다.
"모델 IP 보호가 안 되는 상황에서 어떤 기업이 자사의 핵심 모델을 디바이스에 통째로 넣겠습니까. 결국 온디바이스로 내려오는 건 범용 모델이고, 고부가가치 추론은 여전히 클라우드에 남을 겁니다."
천장은 뚫렸다, 하늘은 아직 멀다
이번 시연이 증명한 것은 '불가능하지 않다'는 사실이다. 2년 전 7B, 작년 70B, 올해 400B. 온디바이스 추론의 상한선이 무서운 속도로 치솟고 있다. 클라우드 AI가 하루아침에 대체되진 않겠지만, 클라우드와 엣지의 경계가 빠르게 허물어지고 있다는 현실은 부정하기 어렵다.
창업자에게는 새로운 제품 카테고리가, 투자자에게는 밸류체인 재배치의 신호가, 반도체 업계에게는 차세대 칩 설계의 방향타가 보이는 시연이었다. 결국 중요한 건 속도가 아니라 방향이다. 그리고 그 방향은 이제 분명히 엣지를 가리키고 있다.