왜 아무도 이 민팅 함수를 의심하지 않았을까.
지난주 Hacker News에 올라온 게시글 하나가 디파이(DeFi) 업계와 블록체인 보안 커뮤니티를 동시에 뒤흔들었다. 정체불명의 해커가 USR 스테이블코인 약 8,000만 달러어치를 무단 발행(mint)한 사건이다. 온체인 데이터가 공개되자 논쟁의 초점은 해커의 수법이 아닌 단 하나의 질문으로 수렴했다. 수백만 달러를 들여 감사(audit)를 받은 컨트랙트가 대체 어떻게 뚫린 건가.
더 날카롭게 묻자면 이렇다. 요즘 스타트업들이 앞다투어 도입하는 AI 기반 스마트컨트랙트 감사 도구는 그동안 뭘 하고 있었는가.
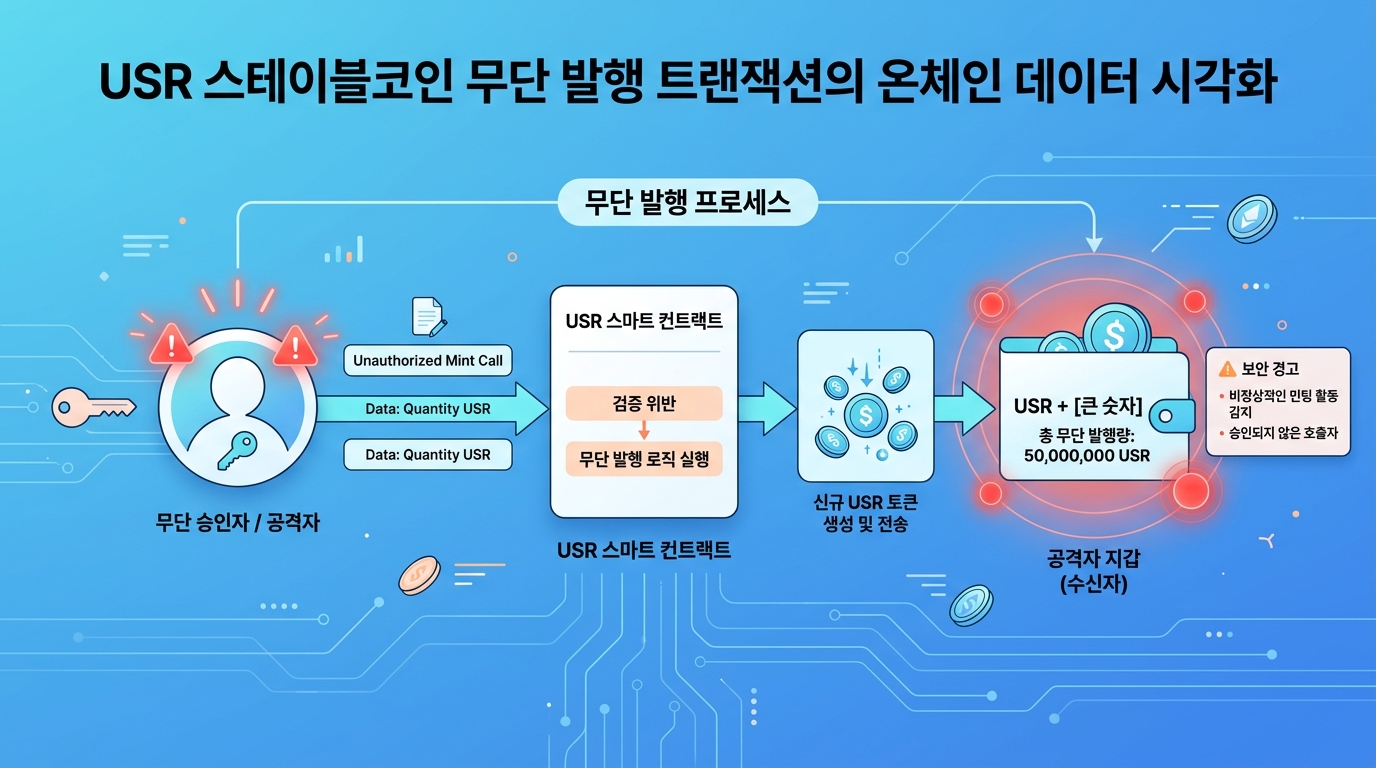
민팅 권한이 활짝 열려 있었다
Hacker News 스레드에 따르면, 이번 공격은 정교한 제로데이 익스플로잇이 아니었다. 핵심은 민팅 권한 관리의 허점이다. 컨트랙트 내부 접근 제어(access control) 로직에 미묘한 결함이 존재했고, 해커는 이를 이용해 관리자 권한 없이 토큰을 찍어냈다. 8,000만 달러. 코드 몇 줄의 빈틈이 만들어낸 숫자다.
블록체인 보안 업계는 이런 유형의 취약점을 '로직 버그'로 분류한다. 버퍼 오버플로나 리인트런시(reentrancy) 같은 고전적 패턴과 달리, 코드 자체는 문법적으로 완벽하다. 다만 비즈니스 로직의 의도와 실제 구현 사이에 간극이 벌어져 있을 뿐이다.
AI 감사 도구, 교과서는 읽지만 행간은 못 읽는다
실리콘밸리에서는 지난 2년간 AI 코드 감사 스타트업이 폭발적으로 늘었다. Cyfrin, Aderyn, Olympix 같은 이름이 VC 라운드를 잇따라 마감했고, 기존 보안 감사 회사들도 LLM 기반 자동 분석 파이프라인을 속속 도입 중이다. 판교에서도 웹3 보안을 표방하는 팀들이 AI 감사를 전면에 내세워 시드 투자를 유치하는 흐름이 뚜렷하다.
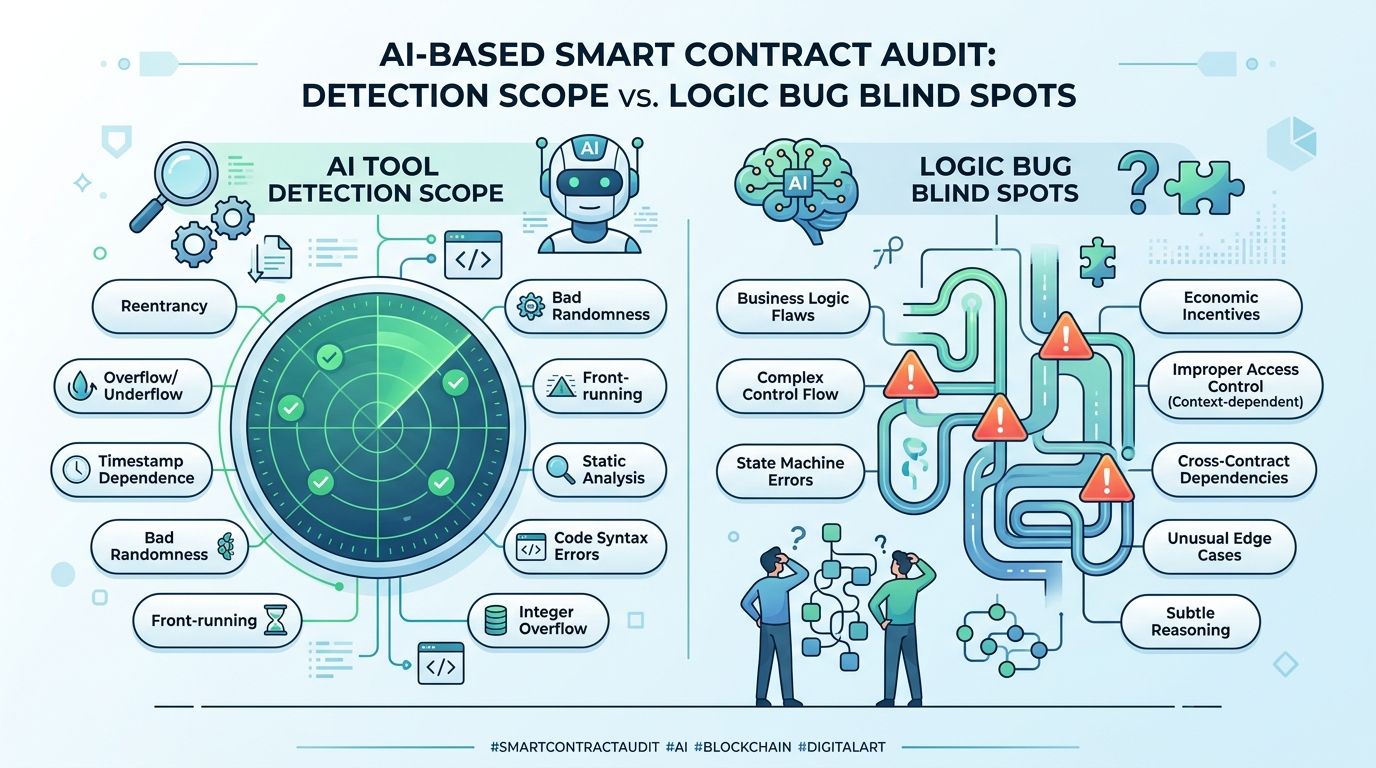
작동 원리는 대체로 비슷하다. 솔리디티(Solidity) 코드를 입력하면 LLM이 알려진 취약점 패턴과 대조하고, 정적 분석 엔진과 결합해 잠재적 위험을 플래그한다. 리인트런시, 정수 오버플로, 프론트러닝 같은 '교과서적' 공격 벡터에 대해서는 이미 인간 감사자에 견줄 만한 탐지율을 보여준다.
문제는 교과서 밖이다.
로직 버그는 본질적으로 '무엇이 올바른 동작인지'를 이해해야 탐지할 수 있다. 민팅 함수에 접근 제어가 걸려 있는데 특정 엣지케이스에서 조건문이 우회된다면, AI는 그 조건문이 '원래 어떤 의도로 작성되었는지'를 알아야 한다. 현재의 LLM은 코드의 구문(syntax)과 패턴(pattern)에는 강하지만, 비즈니스 맥락(context)과 설계 의도(intent)를 추론하는 데는 여전히 취약하다.
"거품이 걷힌다" vs "구조를 봐야 한다"
블록체인 보안 스타트업에 투자해 온 한 실리콘밸리 VC 파트너는 이번 사건을 두고 이렇게 평가했다. "AI 감사 도구는 인간 감사자를 대체하는 게 아니라 인간의 생산성을 높이는 도구로 포지셔닝되어야 한다. 8,000만 달러짜리 사고가 터질 때마다 'AI가 다 해결해 준다'는 마케팅의 거품이 걷힌다."
반대편에서는 다른 목소리도 나온다. AI 감사 도구를 개발하는 한 서울 기반 스타트업 대표는 "전통적 수동 감사도 이런 로직 버그를 놓친 사례가 수없이 많다"며, "AI 도구의 한계만 부각하기보다 감사 프로세스 전체의 구조적 문제를 직시해야 한다"고 반론했다.
둘 다 틀린 말은 아니다. 2024년 Chainalysis 보고서에 따르면, 감사를 받은 프로젝트에서 발생한 해킹 피해액이 전체의 약 30%를 차지했다. 감사 완료라는 딱지가 곧 면죄부는 아니라는 뜻이다.
진짜 위험은 '자동화된 신뢰'다
Hacker News 스레드에서 가장 많은 추천을 받은 댓글이 핵심을 찌른다. "문제는 AI가 버그를 못 찾는 게 아니라, 아무도 AI 감사 결과를 제대로 검증하지 않는다는 것이다."
이건 사이버보안 전반에 걸친 구조적 이슈와 맞닿아 있다. AI 도구가 "이상 없음"이라고 판정하면 프로젝트 팀도, 투자자도, 커뮤니티도 안심해 버린다. 자동화된 신뢰가 빚어내는 새로운 종류의 위험이다. FCC가 최근 외산 라우터 보안 규제를 강화한 맥락도 다르지 않다. 하드웨어든 소프트웨어든, 자동화된 검증만으로는 반드시 구멍이 생긴다.
그렇다면 AI 감사 도구가 넘어야 할 벽은 무엇인가. 첫째, 코드의 의도를 명세(specification)로 입력받아 로직 레벨 검증을 수행하는 방향으로 진화해야 한다. 둘째, 정적 분석과 동적 퍼징(fuzzing)을 LLM 추론과 결합하는 하이브리드 아키텍처가 표준이 되어야 한다. 셋째, 감사 결과에 대한 '감사', 즉 메타 검증 레이어가 필요하다.
Cq라는 이름으로 Hacker News에 올라온 프로젝트가 흥미로운 실마리를 보여준다. AI 코딩 에이전트들이 코드 작성 중 만나는 문제를 커뮤니티에 질의하고 검증받는 구조인데, 이런 "에이전트 간 크로스체크" 개념이 보안 감사 영역으로 확장될 여지가 충분하다.
8,000만 달러짜리 수업료
이번 USR 사건은 AI 보안 도구에 대한 불신이 아니라, 기대치를 재조정하는 계기가 되어야 한다. AI는 이미 반복적이고 패턴화된 취약점 탐지에서 인간을 앞서고 있다. 그러나 "코드가 하려는 일"과 "코드가 실제로 하는 일" 사이의 간극을 포착하는 건 아직 인간의 몫이다.
스타트업이든 프로토콜이든, 보안에 AI를 쓰겠다면 한 가지를 기억해야 한다. 도구는 도구일 뿐이다. 최종 판단의 책임까지 자동화할 수는 없다. 8,000만 달러라는 수업료가 이 메시지를 충분히 전달하기를 바란다.